Ferramentas de Raspagem de Dados Instantâneas: Métodos Rápidos para Extrair Dados da Web Sem Código

Emma Foster
Machine Learning Engineer
TL;Dr: Principais Pontos
- Ferramentas de Extração de Dados Instantâneos permitem que os usuários coletem dados estruturados de sites em segundos sem escrever nenhum código.
- Extensões do navegador como a Extração de Dados Instantâneos são ideais para tarefas simples e únicas, enquanto soluções baseadas em API oferecem melhor escalabilidade.
- Ferramentas modernas usam IA para detectar automaticamente tabelas e listas, reduzindo significativamente o tempo necessário para a preparação dos dados.
- Para sites complexos com medidas de segurança, integrar um solver especializado como CapSolver garante o fluxo ininterrupto de dados.
- Escolher a ferramenta certa depende das suas necessidades específicas em termos de volume, frequência e complexidade técnica do site alvo.
O web scraping evoluiu de uma tarefa complexa de programação para um processo simplificado acessível a todos. Hoje, as Ferramentas de Extração de Dados Instantâneos empoderam marketers, pesquisadores e proprietários de negócios a coletar insights valiosos da web com apenas alguns cliques. Essas ferramentas eliminam a necessidade de scripts Python ou configurações complexas, tornando a extração de dados tão simples quanto navegar em uma página da web. Seja você buscando monitorar preços de concorrentes ou construir uma lista de leads, a ferramenta certa pode poupar centenas de horas de trabalho manual. Este guia explora as maneiras mais eficientes de extrair dados da web sem código, ajudando você a escolher a melhor solução para a sua estratégia de dados de 2026.
Entendendo as Ferramentas de Extração de Dados Instantâneos
O termo Ferramentas de Extração de Dados Instantâneos refere-se a uma categoria de software projetado para coleta de dados imediata de páginas da web. Ao contrário dos scrapers tradicionais que exigem mapeamento manual de seletores, essas ferramentas usam algoritmos heurísticos ou IA para identificar padrões nas estruturas HTML. Isso significa que elas podem reconhecer listas de produtos, feeds de notícias ou resultados de busca automaticamente. O volume global de dados criados e consumidos está crescendo exponencialmente, tornando ferramentas de extração rápida mais críticas do que nunca.
A maioria das Ferramentas de Extração de Dados Instantâneos opera como extensões de navegador ou APIs baseadas em nuvem. Extensões são perfeitas para tarefas rápidas onde você precisa apenas de dados da página que está visualizando atualmente. Ferramentas baseadas em nuvem, por outro lado, são mais adequadas para operações em larga escala, onde você precisa raspar milhares de URLs simultaneamente. Compreender essas diferenças é o primeiro passo para otimizar seu fluxo de coleta de dados.
Principais Ferramentas de Extração de Dados Instantâneos em 2026
O mercado de extração sem código evoluiu significativamente, com vários concorrentes destacando-se. Cada ferramenta oferece recursos únicos adaptados a diferentes necessidades dos usuários. Abaixo está uma comparação das principais ferramentas de Extração de Dados Instantâneos disponíveis atualmente.
Resumo da Comparação: Melhores Extratores de Dados Instantâneos
| Nome da Ferramenta | Tipo | Ideal Para | Facilidade de Uso | Escalabilidade |
|---|---|---|---|---|
| Instant Data Scraper | Extensão do Chrome | Extração rápida de tabelas com um clique | Alta | Baixa |
| ScraperAPI | API em Nuvem | Pipelines automatizadas de alto volume | Média | Alta |
| Octoparse | Aplicativo de Desktop | Sites complexos com paginação | Média | Média |
| WebScraper.io | Extensão | Conteúdo dinâmico e sitemaps | Média | Média |
| Data Miner | Extensão | Receitas prontas para sites populares | Alta | Média |
1. Instant Data Scraper (Extensão do Chrome)
Talvez a escolha mais popular para iniciantes. É uma extensão do navegador gratuita que usa IA para prever quais dados são mais relevantes em uma página. Quando você clica no ícone da extensão, ela destaca imediatamente a tabela ou lista detectada e fornece uma prévia dos dados. É uma das formas mais eficazes de extrair dados da web sem código porque não requer nenhuma configuração.
A ferramenta suporta rolagem infinita e botões "Localizar Próximo" para paginação. Isso permite que você raspe várias páginas de resultados de busca sem intervenção manual. No entanto, como ela roda localmente no seu navegador, não é adequada para raspar milhões de páginas ou lidar com proteções pesadas contra scraping. Para aqueles que buscam opções mais robustas, verificar as melhores ferramentas de extração de dados pode oferecer uma visão mais ampla sobre soluções de nível corporativo.
2. ScraperAPI DataPipeline
Para usuários que precisam de mais do que apenas uma extensão do navegador, o ScraperAPI oferece uma solução de baixo código chamada DataPipeline. Esta ferramenta permite que você carregue uma lista de URLs e receba dados estruturados em formato JSON ou CSV em retorno. Ela lida automaticamente com obstáculos técnicos como rotação de IPs e gerenciamento de cabeçalhos.
Uma das principais vantagens de usar ferramentas de Extração de Dados Instantâneos baseadas em API é a capacidade de contornar restrições comuns. Muitos sites usam métodos sofisticados para identificar e bloquear tráfego automatizado. Ao usar um serviço que sabe como evitar bloqueios de IP, você pode garantir que sua coleta de dados permaneça consistente e confiável.
Superando Desafios na Extração de Dados Instantâneos
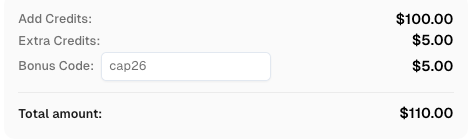
Use o código
CAP26ao se inscrever no CapSolver para receber créditos extras!
Embora as Ferramentas de Extração de Dados Instantâneos sejam extremamente poderosas, elas frequentemente enfrentam obstáculos em sites modernos. Medidas de segurança como CAPTCHAs e sistemas de detecção de bots são projetadas para impedir o acesso automatizado. Isso é onde um scraper padrão pode falhar, deixando você com dados incompletos ou um endereço IP bloqueado.
Para manter um processo de extração sem interrupções, muitos profissionais integram seus scrapers com serviços especializados. Por exemplo, o CapSolver fornece uma camada essencial de suporte ao lidar com desafios complexos de verificação. Ao usar um solver confiável, você pode garantir que suas Ferramentas de Extração de Dados Instantâneos possam acessar até os sites mais protegidos sem serem marcados como bots. Isso é particularmente importante ao lidar com os prompts "I'm not a bot" que frequentemente aparecem durante o scraping de alta frequência.
Funcionalidades Essenciais para Procurar
Ao avaliar Ferramentas de Extração de Dados Instantâneos, você deve priorizar funcionalidades que estejam alinhadas com seus objetivos de longo prazo. Uma ferramenta que funciona hoje pode não ser suficiente à medida que suas necessidades de dados crescem. Considere os seguintes critérios:
- Reconhecimento Automático de Padrões: A ferramenta deve identificar listas e tabelas sem entrada manual de seletores.
- Suporte à Paginação: Capacidade de lidar com botões "Carregar Mais", rolagem infinita e páginas numeradas.
- Opções de Exportação: Suporte aos formatos CSV, Excel e JSON para integração fácil com outros softwares.
- Execução em Nuvem: A opção de executar tarefas de scraping em um servidor em vez de sua máquina local.
- Integração com Anti-Deteção: Compatibilidade com proxies e solvers de CAPTCHA para manter altas taxas de sucesso.
Como Usar um Extrator de Dados Instantâneos: Um Guia Passo a Passo
Usar Ferramentas de Extração de Dados Instantâneos geralmente é simples. A maioria das ferramentas segue um fluxo de trabalho semelhante que prioriza velocidade e simplicidade. Aqui está como você pode começar a extrair dados em minutos:
- Instale a Ferramenta: Baixe a extensão da Chrome Web Store ou se inscreva em um serviço baseado em nuvem.
- Navegue até o Site Alvo: Abra a página da web contendo os dados que você quer extrair, como uma página de categoria de e-commerce.
- Ative o Extrator: Clique no ícone da ferramenta. A IA destacará a área de dados detectada.
- Refine a Seleção: Se a ferramenta perder uma coluna, você geralmente pode clicar para adicioná-la manualmente.
- Lide com a Paginação: Se os dados se estenderem por várias páginas, use a função "Localizar Próximo" para guiar o extrator.
- Baixe Seus Dados: Após a extração ser concluída, exporte os resultados para o formato de sua preferência.
Para usuários mais avançados, seguir o Padrão WebDriver da W3C pode ajudar a entender como essas ferramentas interagem com ambientes de navegador em um nível mais profundo.
O Papel da IA na Extração de Dados Moderna
A nova geração de Ferramentas de Extração de Dados Instantâneos é fortemente influenciada pela Inteligência Artificial. A IA permite que essas ferramentas entendam o contexto de uma página em vez de apenas seu código. Por exemplo, um extrator com IA pode distinguir entre um preço de produto e um preço com desconto, mesmo que as tags HTML sejam semelhantes.
Essa mudança para extração inteligente está tornando as ferramentas de scraping sem código de 2026 mais confiáveis do que nunca. À medida que os sites se tornam mais dinâmicos e complexos, a capacidade de uma ferramenta de se adaptar às mudanças de layout sem intervenção do usuário é uma grande vantagem competitiva. Por isso, muitas empresas estão se afastando de scrapers rígidos baseados em seletores em favor de soluções mais flexíveis e instantâneas.
Conclusão
O surgimento das Ferramentas de Extração de Dados Instantâneos democratizou o acesso aos dados da web, permitindo que qualquer pessoa se torne um tomador de decisões baseado em dados. Ao escolher a ferramenta certa — seja uma extensão simples para tarefas rápidas ou uma API robusta para projetos em larga escala — você pode acelerar significativamente sua pesquisa e operações. Lembre-se de que as estratégias de scraping mais bem-sucedidas frequentemente envolvem uma combinação de formas rápidas de extrair dados da web sem código e serviços especializados como CapSolver para lidar com desafios de segurança. Ao construir sua pipeline de dados, foque na escalabilidade e confiabilidade para garantir que seus insights permaneçam precisos e oportunos.
Perguntas Frequentes
1. As ferramentas de web scraping instantâneo são legais para uso?
Sim, o web scraping é geralmente legal para dados publicamente disponíveis. No entanto, você deve sempre respeitar o arquivo robots.txt de um site e seus termos de serviço. Para mais detalhes, você deve consultar recursos legais sobre ética de coleta de dados e regulamentações regionais.
2. Posso raspar sites que exigem login?
Algumas das melhores extensões de web scraper para Chrome podem lidar com sessões autenticadas porque usam seus cookies. No entanto, scrapers baseados em nuvem geralmente exigem configurações mais complexas para lidar com autenticação.
3. Qual a diferença entre uma extensão de navegador e uma API de scraping da web?
Uma extensão roda no seu navegador e é ideal para tarefas pequenas. Uma API roda em um servidor remoto, permitindo volume muito maior e melhores capacidades de automação.
4. Como lidar com CAPTCHAs durante o scraping?
A maneira mais eficaz é usar um serviço dedicado como CapSolver. Ele se integra com sua extração automatizada de dados para qualquer fluxo de trabalho de site para resolver desafios em tempo real, garantindo que seu scraper nunca fique travado.
5. Preciso conhecer HTML para usar essas ferramentas?
Embora conhecimento básico da estrutura HTML seja útil, a maioria dos scrapers instantâneos é projetada para funcionar sem conhecimento técnico. Para aqueles interessados na tecnologia subjacente, a Especificação de Tabela HTML da W3C fornece uma análise aprofundada sobre a organização de dados na web.
Ver mais
web scrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.

web scrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

